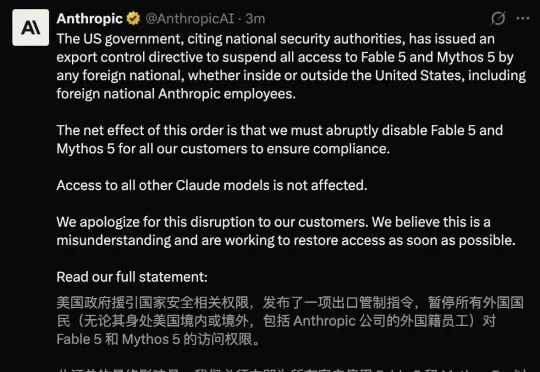
6月12日(美东时间),Anthropic在官网发声明:"对Claude Fable 5和Mythos 5的所有访问。为合规,我们必须立刻为所有客户禁用这两个模型。"

不是降价,不是限流,是直接全局关停。
所有正在跑Claude Fable 5的会话中断报错,API调用返回错误,用户被自动降级回 Claude Opus 4.8。Anthropic同时开了退款通道,按剩余时长折算退费,截止6月20日。
最关键的。Anthropic发现,Fable 5展现出了一些连研发团队都难以解释的“涌现能力”。为了防止模型在无人监管的情况下产生不可预知的行为(即业内常说的Alignment Problem对齐问题)。
对于我们来说,有什么影响?
最直接的影响是:Fable 5 当前不可用。
准备用它做大型代码项目、复杂研究、长文档分析,那么短期内会受到影响,但也要说清楚:这不等于 Claude 全线停摆。Anthropic 已明确表示,其他模型不受影响。对于国内的独立开发者和出海团队来说,这无异于一次降维打击。
别慌,我们找到了2款平替方案(附实测数据)
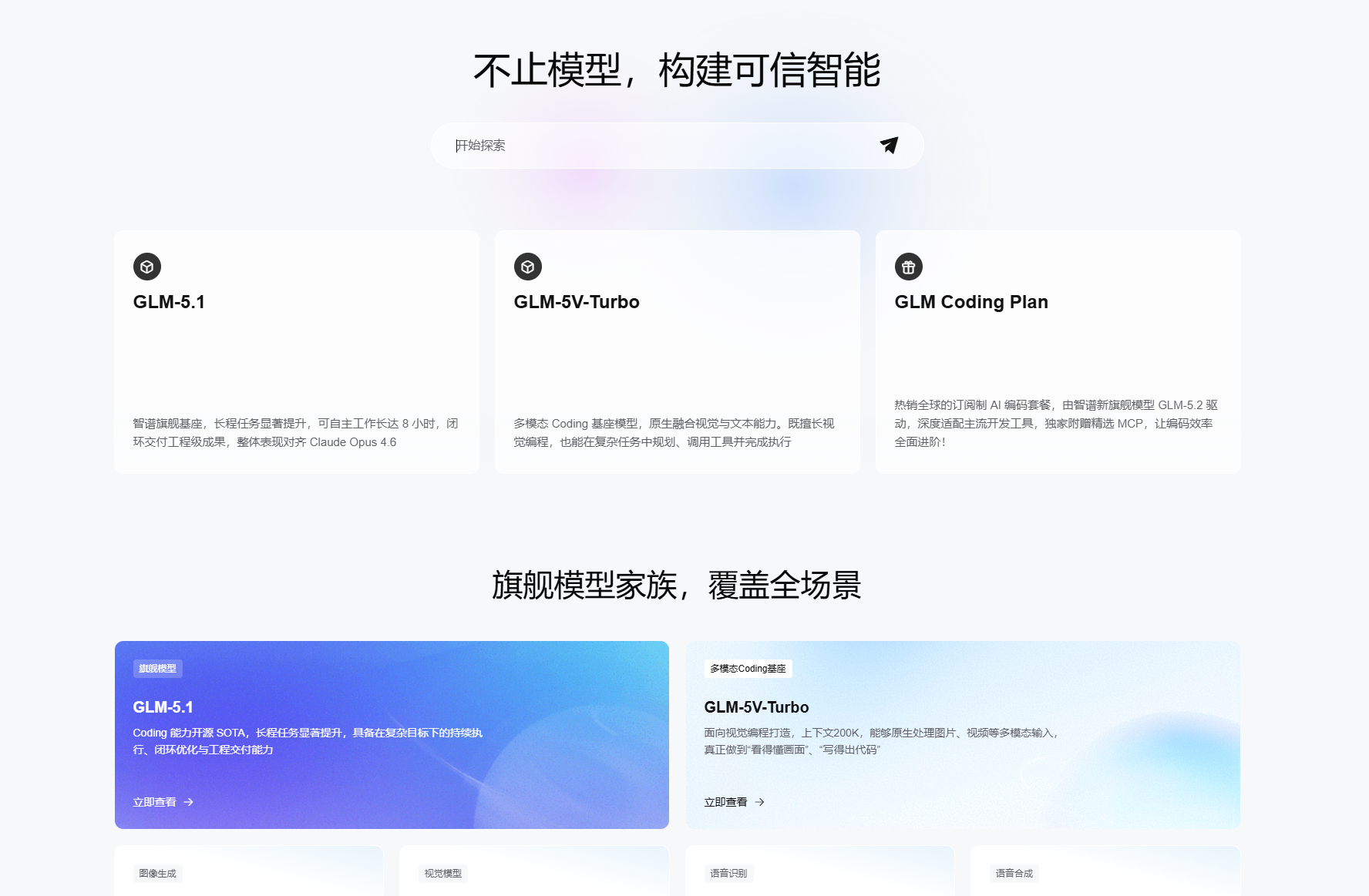
1、GLM-5.2 —— 这是目前最接近“Fable 5平替”的国产模型
如果你是冲着 Fable 5 的长程 Coding 和复杂工程能力来的,GLM-5.2 是当前国产模型中最直接的平替。
GLM-5.2 支持真正可用的1M上下文。上一代 GLM-5.1在 SWE-bench Pro 上已经取得 58.4%的得分,超过了当时的GPT-5.4和 Claude Opus 4.6;5.2 在此基础上进一步全面强化:支持12小时以上的稳定 Agent 任务,生成速度提升至 500+ tokens/s,复杂推理幻觉率再降 30%。
2.、DeepSeek V4.1 —— 代码能力飙升,性价比高
这个适合每天高频调用的场景:写CRUD、写脚本、生成表单、改bug、翻译文档、解释代码逻辑。
DeepSeek V4.1 还在灰度,但已经测了不少——有人用金门大桥的 three.js 场景测试,结论是代码能力 V4.1 Flash 和原 V4.0 比是“天差地别的提升”,V4-Pro 的基准已经放出:SWE-bench 83.7%,LiveCodeBench 93.5%,Codeforces 3206 分(一梯队水平)。
价格方面,Flash 输出 $0.28/1M,Pro 输出 $3.48/1M。而且 V4-Pro 的 SWE-bench 83.7% 确实压过了 Claude Opus 4.6(约80%)。
如果一定要二选一而且对价格敏感,Flash 的成本控制比 GLM 还狠一个量级;如果追求性能上限,GLM-5.2 旗舰版更稳。

您好,如有软件收录需求,请将软件打包,并附上软件名称、软件介绍、软件相关截图、软件icon、软著、营业执照(个人没有营业执照请提供对应的开发者身份证正反面以及手持身份证本人照片),发送至邮箱
https://user.onlinedown.net/login扫码添加企业微信

如有产品建议或问题反馈,欢迎告诉我们,您的意见是我们进步的动力!
扫码添加官方公众号